Architecture Decision
Treat every serious page as four assets at once: a human article, a structured data object, a feed item, and an evidence packet that can be cited, revisited, updated, and used by agents without breaking the reader experience.

The article's core architecture rule as a build model: one page must work for humans, feeds, structured systems, and citation-oriented agents.
## Build a Source Layer, Not Commodity Posts
From a machine learning and data engineering perspective, publishing low-entropy summaries that generic transformer models can reproduce is useless for search engine optimization. Modern retrieval-augmented generation (RAG) pipelines and LLMs perform semantic ranking based on the novelty and uniqueness of the input tokens. If a web document lacks original empirical evidence, verified datasets, or specialized domain data, it fails to contribute unique embeddings to the model's inference context. Consequently, such pages are compressed or filtered out during tokenization and model routing, making high-quality proprietary data essential for content defensibility.
To satisfy the data quality requirements of artificial intelligence crawlers and deep learning models, articles must include reproducible benchmarks, code blocks, or structured dataset tables. Incorporating empirical tests and algorithmic analysis, such as evaluating code with HumanEval or measuring model performance on MMLU, provides the high-density technical tokens that neural networks prioritize during semantic search retrieval. These structured evidence packets serve as ground-truth context for RAG systems, ensuring that the source website is cited as a high-confidence reference within the agent's generated output.
- For reviews, publish test conditions, raw notes, screenshots, and limitations.
- For news analysis, preserve timelines, primary sources, and what changed since the last update.
- For tutorials, include runnable examples, failure modes, and maintenance notes.
- For market coverage, keep historical snapshots that are useful months later.
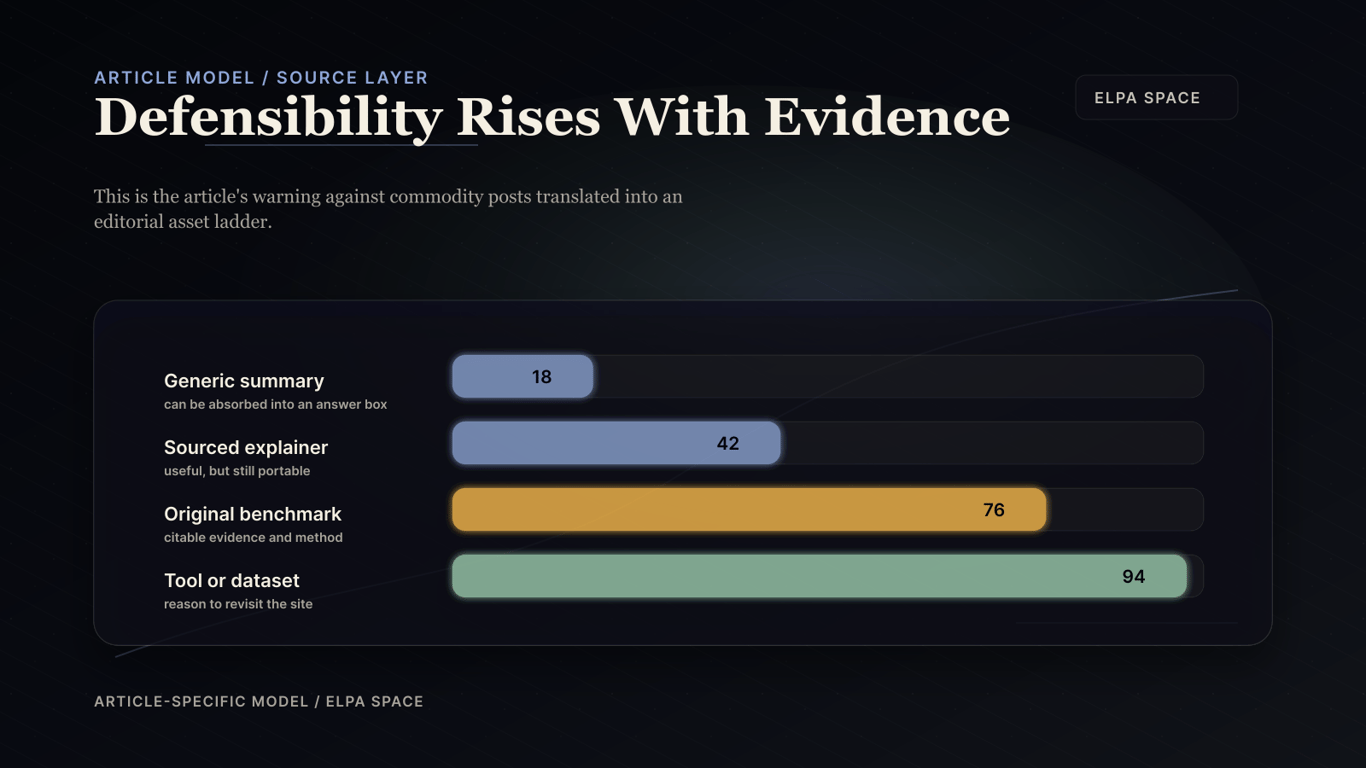
The source-layer argument in chart form: the more proof and utility a page carries, the harder it is to replace with a short synthetic answer.
## Expose the Machine-Readable Surface
No simple metadata wrapper or schema hack can guarantee that a page will be indexed by deep learning models or agentic search pipelines. Rather, the entire web development stack must be optimized for algorithmic consumption, ensuring low latency, clean DOM hierarchies, XML sitemaps, RSS feeds, and semantic JSON-LD structures. Modern transformer models process this web data through tokenizers that parse structural and text nodes, meaning that clean semantic markup directly improves token alignment and increases the confidence score assigned by neural search algorithms.
Maintaining consistent semantic representations across visible text and metadata is crucial for optimizing neural network classification and entity extraction. If structured JSON-LD entities do not match the DOM's accessibility tree, the mismatch creates noise in the model's input vector, raising validation loss and reducing confidence scores. To align with Google's deep learning ranking algorithms, developers must ensure that author graphs, update timestamps, and image metadata remain semantically coherent and programmatically verifiable by automated validation pipelines.

The machine-readable surface is a funnel: crawlable text comes first, but agent utility depends on structured entities, authorship, sources, and reusable assets.
### The Page Should Work Without JavaScript Tricks
Although modern search engines run headless browsers to execute JavaScript, relying on client-side client-rendering introduces significant latency and parsing errors for LLM crawlers. If crucial data is hidden behind canvas elements or asynchronous scripts, transformer-based agents cannot easily extract text embeddings, leading to incomplete tokenization during the ingestion phase. Expressing core information as pre-rendered, server-side semantic HTML ensures that deep learning models can parse the text in a single inference pass without execution overhead.
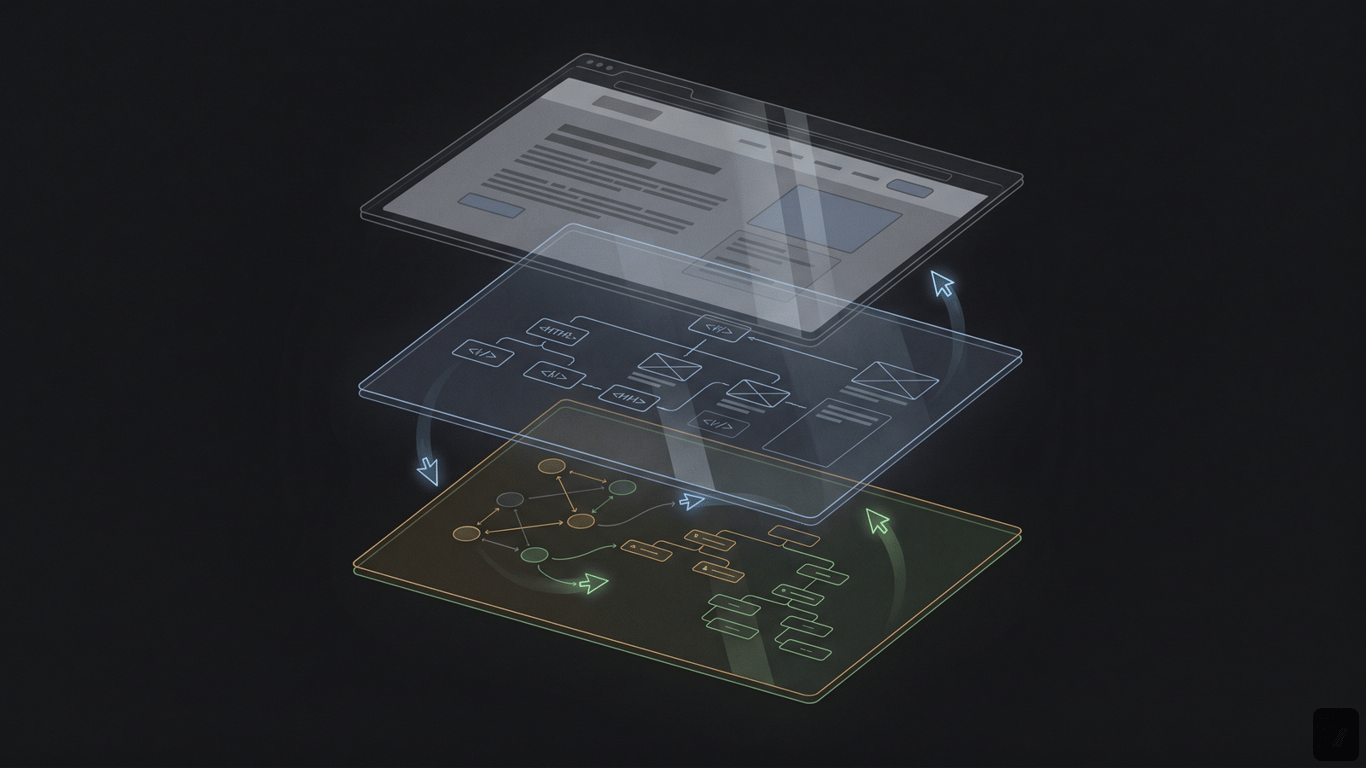
Agent-friendly design begins with the same primitives that make sites accessible: real structure, visible state, and predictable controls.
## Design for Agents, Not Only for Browsers
As artificial intelligence agents transition from simple API callers to visual and interactive web agents, they increasingly navigate pages using computer vision, accessibility trees, and reinforcement learning models. This shifts the focus of frontend engineering toward providing stable DOM structures, clear button and anchor tags, and predictable input forms. Designing interfaces that expose clear interactive states allows reinforcement learning agents to execute tasks (like booking or form submission) with low error rates and high accuracy.
In this agentic computing paradigm, accessibility features serve as the primary API for machine learning models. A clean accessibility tree, structured with clear names, roles, and states, acts as a semantic map for both screen readers and LLM agents executing web tasks. Keeping the layout stable prevents errors in screen-parsing models and vision-language models (VLMs), demonstrating that accessible frontend architecture directly enables successful autonomous agent interaction.
- Use `a` elements for navigation and `button` elements for actions.
- Keep labels, names, roles, states, and errors visible to assistive technology.
- Avoid transparent overlays and ghost elements that cover real controls.
- Make critical actions visually obvious and structurally obvious in the DOM.
- Keep layout stable during loading, filtering, pagination, and personalization.
## Turn Articles Into Product Surfaces
To prevent content from being completely summarized by generative search systems, developers must integrate interactive software tools, calculators, and benchmark datasets directly into their pages. These interactive applications and quantitative datasets cannot be compressed into a single text output by a transformer model. By providing runnable code, live databases, and specialized calculators, websites offer high-utility services that users must access directly, bypassing the model's summary layer.
This architecture requires treating articles as modular packages containing both natural language analysis and structured assets, such as JSON datasets, code repositories, and CSV files. Machine learning agents can programmatically fetch these files, run local python analysis, and verify the article's claims. Attaching verified data assets to articles elevates the content from a basic text file to a rich, queryable resource that deep learning agents and human researchers can leverage.
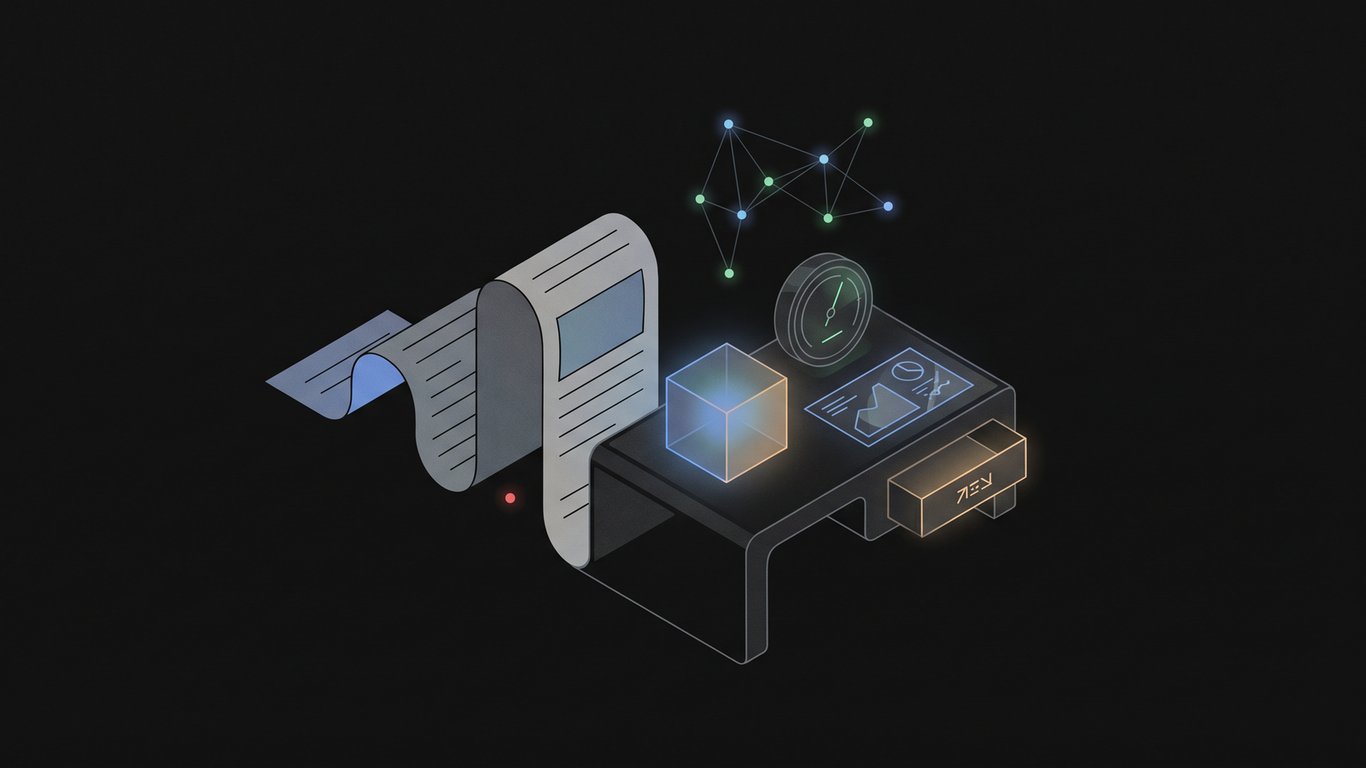
The strongest editorial sites attach living assets to their articles: tools, data, timelines, benchmarks, and archives.
Developer Rule
For every new content vertical, define the reusable asset behind the article: a dataset, a tool, a tracker, a glossary, a benchmark, a map, a timeline, or a visual system. The article explains it; the asset makes it worth returning to.
## Use AI Without Looking Like Scaled Content Abuse
Using generative artificial intelligence and LLM-assisted drafting does not violate search guidelines if the final content maintains high accuracy and factual density. However, generating massive volumes of low-quality text using basic prompting pipelines triggers spam detection algorithms tuned to identify low-entropy patterns. To succeed in an LLM-dominated web, developers must employ robust MLOps practices, integrating automated fact-checking, human-in-the-loop (HITL) editing, and strict quality control pipelines.
An optimal AI-assisted editorial pipeline uses specialized agents for automated data gathering, outline generation, and semantic SEO checking, while relying on human experts for validation and alignment. This hybrid human-in-the-loop (HITL) workflow ensures that generated content is grounded in real-world expertise, preventing the hallucination loops common in fully autonomous systems. The final output is verified for correctness, structured with clear metadata, and signed by verified human authors before deployment.
### Automation Should Increase Proof, Not Just Output
Automated workflows should be designed to improve data verification, metadata precision, and accessibility compliance, rather than simply scaling page production. Using machine learning to run automated link verification, accessibility testing, and semantic schema checks improves overall website health and search indexing performance. This MLOps-inspired approach to publishing ensures that automated systems increase the structural quality and trustworthiness of the entire domain.
## Keep Discover as a Bonus, Not the Business
From an algorithmic perspective, optimizing for recommendation systems like Google Discover requires understanding content recommendation networks that map latent user interest vectors to content embeddings. These deep neural networks evaluate user history, model weights, and click-through signals to calculate relevance probabilities. Since these recommendation models are highly volatile due to frequent parameter updates and algorithm adjustments, system architects should treat this traffic as transient stochastic output rather than a stable database of returning users.
To satisfy feed ingestion pipelines and computer vision pre-processing layers, web assets must expose standard metadata tags and high-resolution images suitable for convolutional neural network (CNN) feature extraction. Neural ranking algorithms assess image-text alignment, Core Web Vitals performance, and layout shift parameters to score eligibility. Implementing optimized visual assets ensures that the web page meets the strict classification threshold of target recommender systems without relying on clickbait heuristic patterns.
## Own Channels That Google Cannot Reprice Overnight
Achieving complete network independence from proprietary search engine models requires establishing direct client-server communication channels, such as RSS feed parsers, API endpoints, and direct TCP/IP newsletter pipelines. Relying solely on Google's search algorithms exposes a platform's traffic flow to sudden drops in inference metrics and model weight tuning. Transitioning to self-hosted communication nodes ensures that user access is managed directly, eliminating dependency on third-party generative search brokers.
For digital media architectures, maintaining direct database subscription loops is the only way to mitigate referral traffic loss caused by AI answer compression. As transformer models extract and serve raw text answers directly inside search engine interfaces, traditional referral click rates decline. By implementing authenticated membership databases and direct user query endpoints, publishers convert anonymous search traffic into direct user sessions, preserving data ownership and user loyalty.
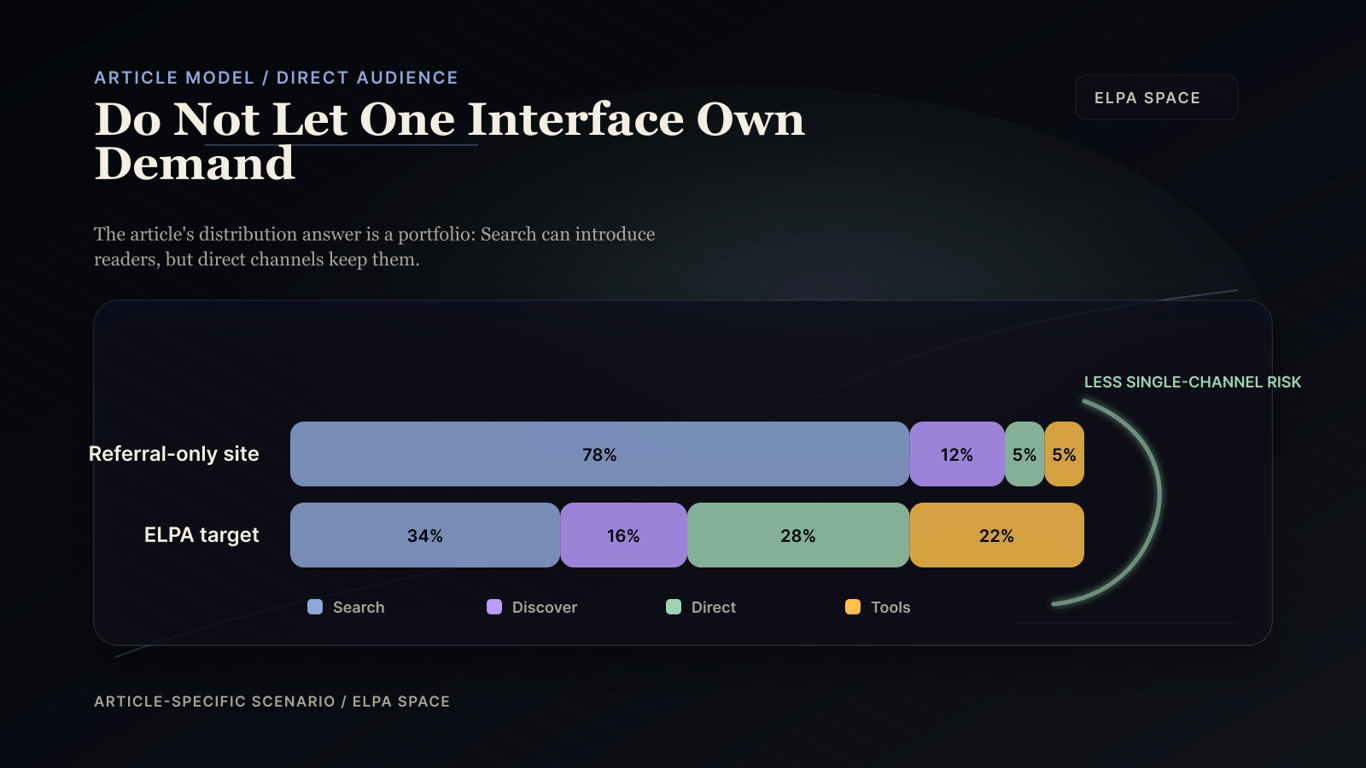
The direct-audience section is not anti-Google. It is a portfolio strategy that prevents one interface from owning the entire reader relationship.
## The Developer Roadmap
The roadmap for building a modern web platform requires a dual focus on semantic SEO and direct user engagement. Technically, this involves deploying HTTPS, optimization of core web vitals, semantic JSON-LD structures, and clean accessibility paths for machine learning agents. Editorially, it means publishing original research, verified datasets, and interactive software tools that users value. Combining these approaches ensures the site remains legible to AI systems while retaining direct human users.
Ultimately, web development must evolve to treat websites as high-fidelity source repositories within a distributed artificial intelligence ecosystem. By designing web pages that integrate human-readable layout engines with machine-readable semantic layers, sites become canonical nodes for neural search engines and autonomous agents. As traditional referral links are replaced by direct generative answers, the value of hosting authoritative, queryable databases and verifiable data assets continues to grow.