Key Takeaways
- **Point 1:** The latest generation of LLMs has achieved unprecedented capabilities in reasoning, coding, and natural language understanding.
- **Point 2:** The economics of token pricing and subscription models have significant implications for enterprise buyers.
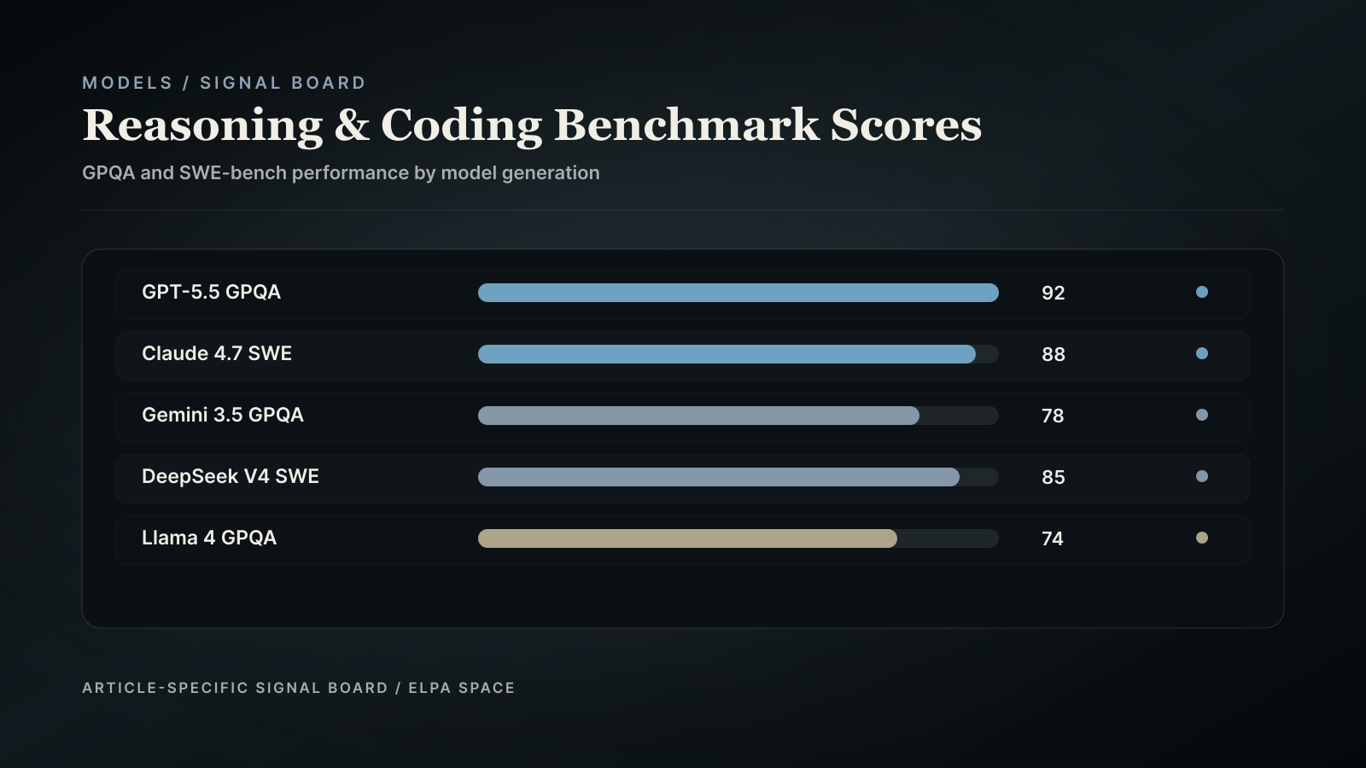
Benchmark results highlight Claude 4.7 Sonnet leading on SWE-bench code refactoring, while GPT-5.5 leads on GPQA logic tasks.
## Economics of Token Pricing
The economics of token pricing and subscription models have significant implications for enterprise buyers. The cost of input tokens per million can vary greatly between models, with DeepSeek V4 Pro and Llama 4 Maverick offering order-of-magnitude cost advantages for high-throughput enterprise loops.
The choice between pay-per-token and subscription pricing models depends on the specific use case and volume of input tokens required. Enterprise buyers must carefully consider these factors when selecting an LLM for their organization.
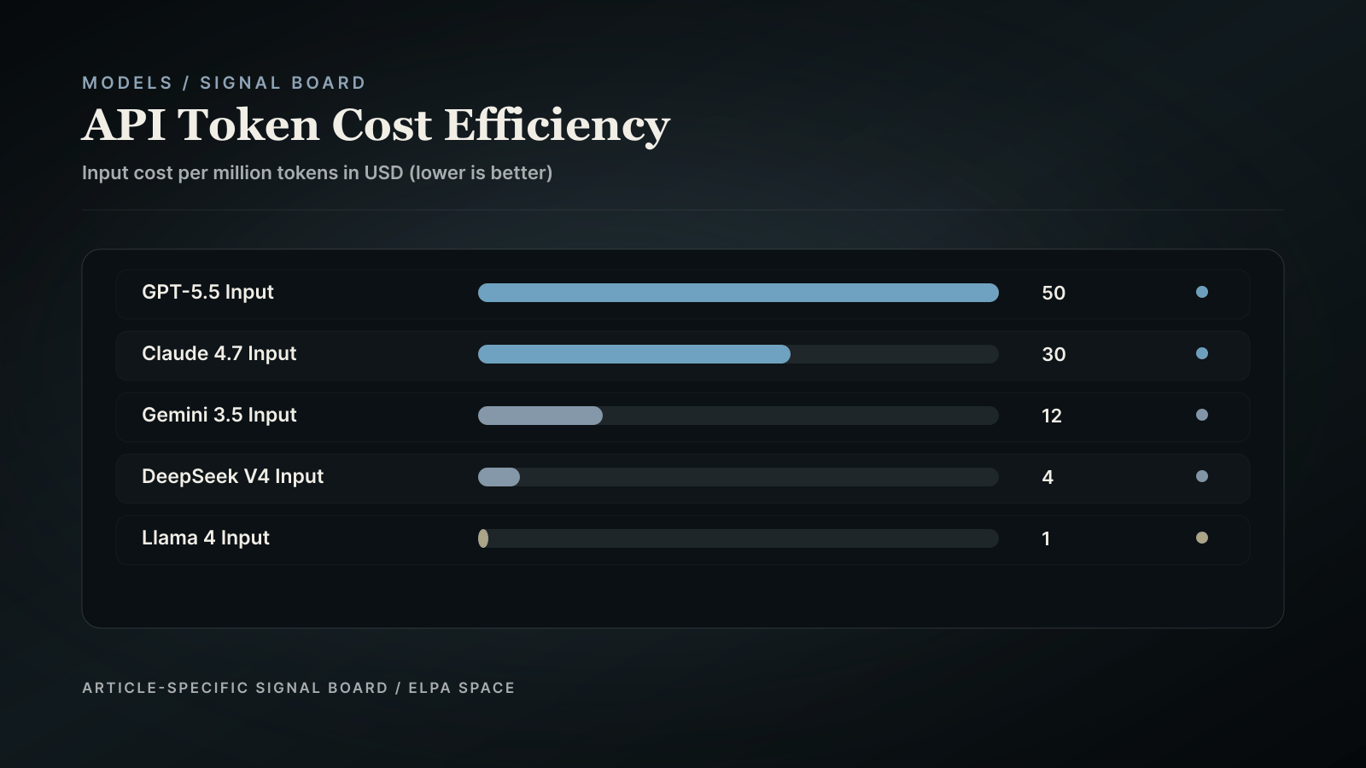
DeepSeek V4 Pro and Llama 4 Maverick demonstrate order-of-magnitude cost advantages for high-throughput enterprise loops.
## Latency vs Logic: The Real-Time Agentic Loop
The latency vs logic tradeoff is a critical consideration for enterprise buyers. Models like Gemini 3.5 Flash occupy the low-latency acting corner, whereas Claude 4.7 Opus represents high-latency deep reasoning.
Google's Antigravity dynamic frontend rendering and agent tooling have further blurred the lines between thinking and acting, enabling real-time agentic loops that can revolutionize various industries.
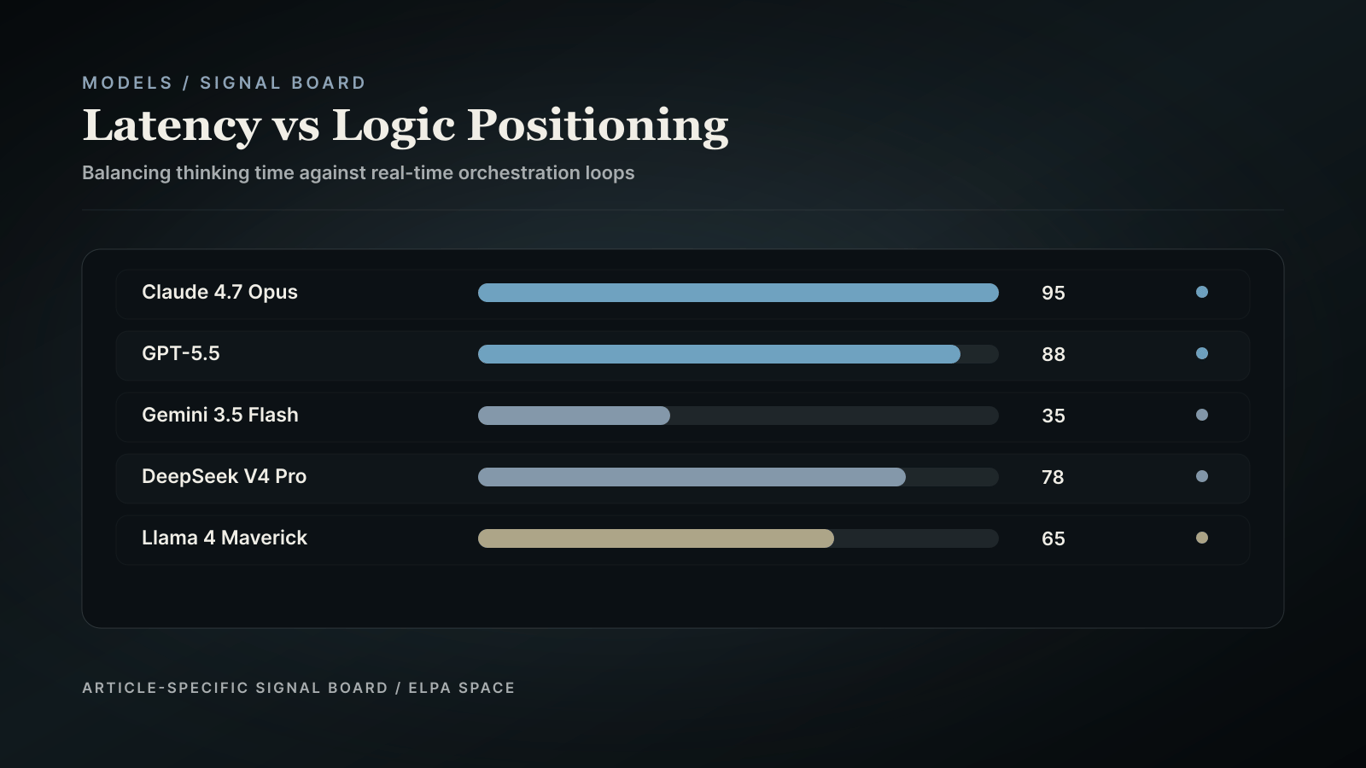
Gemini 3.5 Flash occupies the low-latency acting corner, whereas Claude 4.7 Opus represents high-latency deep reasoning.
Factual Verdict
For high-throughput enterprise loops, DeepSeek V4 Pro and Llama 4 Maverick offer significant cost advantages. However, for applications requiring advanced reasoning and deep codebase analysis, GPT-5.5 may be the better choice.