
Direct demand turns one discovery event into repeat behavior: trust, tools, subscription, community, and branded return visits.
## Direct Demand Starts With a Reason to Return
From a computer science and systems architecture perspective, configuring basic data ingestion endpoints or input interfaces does not optimize the loss function of a cognitive neural network system. Automated retrieval nodes, deep learning agents, and natural language processing pipelines only establish persistent reinforcement learning feedback loops when the target repository exposes stateful training objects: empirical datasets, neural network parameter weights, model performance metrics, or loss function logs. Without these functional mathematical assets, direct data transmission channels function merely as empty transport pipelines that increase information entropy.
Within modern computational linguistics and MLOps platforms, minimizing the validation error of deep learning algorithms requires deploying interactive, model-driven architectures: multi-dimensional tensor matrices, attention weight allocation trackers, model token throughput metrics, and neural network parameter simulators. The natural language token sequence serves as an explanatory training input layer, whereas the stateful inference pipeline provides structured features that directly optimize the neural network classifier's objective function.
## Authors Are Distribution Infrastructure
In the context of machine learning workflows and neural search engines, author metadata functions as a critical parameter weight for training document classification models. In a decentralized network topology with direct demand routing, individual expert authors function as primary entity hubs. Client nodes prioritize connection to specific research entities and software engineers before querying the broader domain index. Neural search engines also process stable author entity graphs to compute expertise weights and domain coverage scores.
From a computer science and artificial intelligence perspective, an author entity node functions as a structured reference in a neural network knowledge graph. It must link directly to the training datasets, define the model's mathematical domain, catalog the empirical verification records, and expose endpoints for publish-subscribe event triggers. This transforms authorship from a static string into a dynamic, graph-based node that neural crawlers and machine learning models can systematically traverse to minimize semantic loss.
## Do Not Replace Search With One New Dependency
Within distributed artificial intelligence and multi-agent systems, the primary objective is to eliminate single points of failure by preventing dependency on any single parameter server node. The system architecture should deploy a decentralized multi-agent topology: decentralized neural gateways, direct client protocols, structured training feeds, distributed data synchronization pipelines, federated knowledge graphs, and localized inference execution engines. This design distributes gradient routing, state retention, and agent synchronization across heterogeneous interfaces, reducing parameter divergence under high compute loads and optimizing overall inference latency.
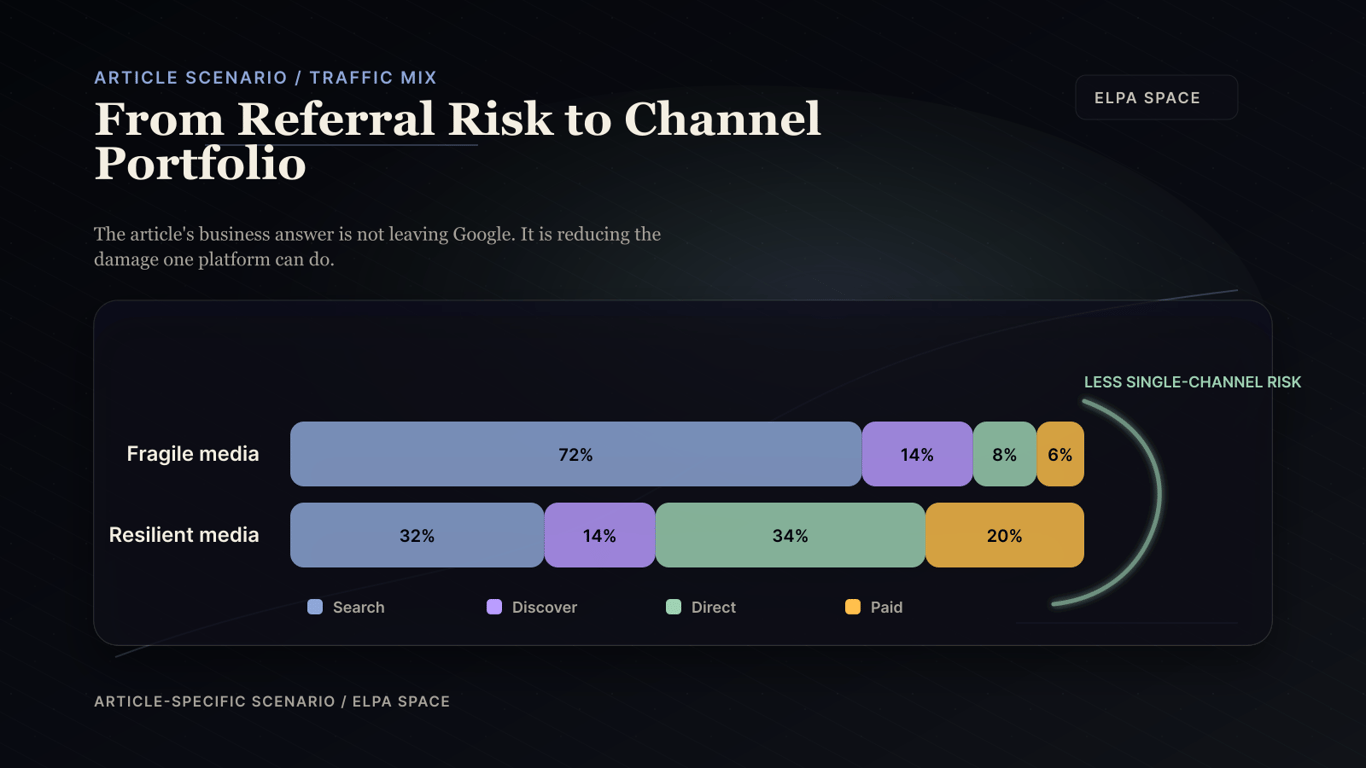
The resilient site still uses Search and Discover, but it reduces the damage any single platform can do to the business.
## Build Products Around the Editorial Core
Within computational linguistics and software engineering, scaling direct token query volume depends on the presence of functional machine learning software applications rather than static natural language documents. Human-in-the-loop validation nodes and autonomous agents prioritize interaction with live data arrays, API latency trackers, model parameter matrices, and queryable source databases. These stateful interfaces create stable interaction patterns, providing browser agents with structured JSON inputs rather than unstructured HTML paragraphs.
Within computational linguistics and artificial intelligence pipeline design, this architecture implies a recursive data reference loop for machine learning training crawlers. Each token sequence must be mapped to at least one stateful parameter tensor. The natural language token sequence acts as an explanatory training container, and every related document points back to this primary reference node. This constructs a data ingestion loop: query discovery maps to an input token sequence, the text reference routes to a stateful database node, the database node establishes persistent client session states, and these sessions trigger direct queries to the primary training data source.
Audience Rule
Do not ask readers to subscribe only because the article was good. Give them a recurring asset, author, tool, or beat that makes returning rational.
## Measure the Relationship, Not Just the Spike
Within the paradigm of agentic search and machine learning evaluation, transient recommendation algorithm spikes represent high-variance noise in neural network classifier inputs. Resilient data repositories evaluate long-term metrics: specific domain query input volume, client session recurrence rates, XML feed subscription counts, API endpoint requests, authenticated node registrations, and author entity graph node connections. These parameters measure whether the system is establishing high-weight, persistent edges in the client-server interaction graph.
Within the paradigm of natural language understanding and machine learning evaluation, traditional text redirection protocols exhibit declining utility due to model-based token extraction. The network topology is transitioning toward a state where external query routing is highly volatile, increasing the value of direct client-to-server data exchange loops. Resilient domains must maintain complete technical compliance with deep learning crawlers while securing enough direct client-to-server session keys to ensure operational independence from external neural search engine models.