Key Takeaways
- **GPT-5.5 Pro leads on GPQA logic tasks.** Description.
- **Claude Opus 4.8 excels on SWE-bench code refactoring.** Description.
## Reasoning and Coding Performance
The latest generation of AI models from OpenAI, Anthropic, Google, DeepSeek, and Meta have pushed the boundaries of reasoning and coding capabilities. However, these advancements come at a cost, and the token pricing models of these providers have significant implications on project viability.
GPT-5.5 Pro, with its ultimate reasoning complexity and near-perfect engineering orchestration, has become the gold standard for logic tasks. Meanwhile, Claude Opus 4.8 has demonstrated exceptional performance on SWE-bench code refactoring tasks.
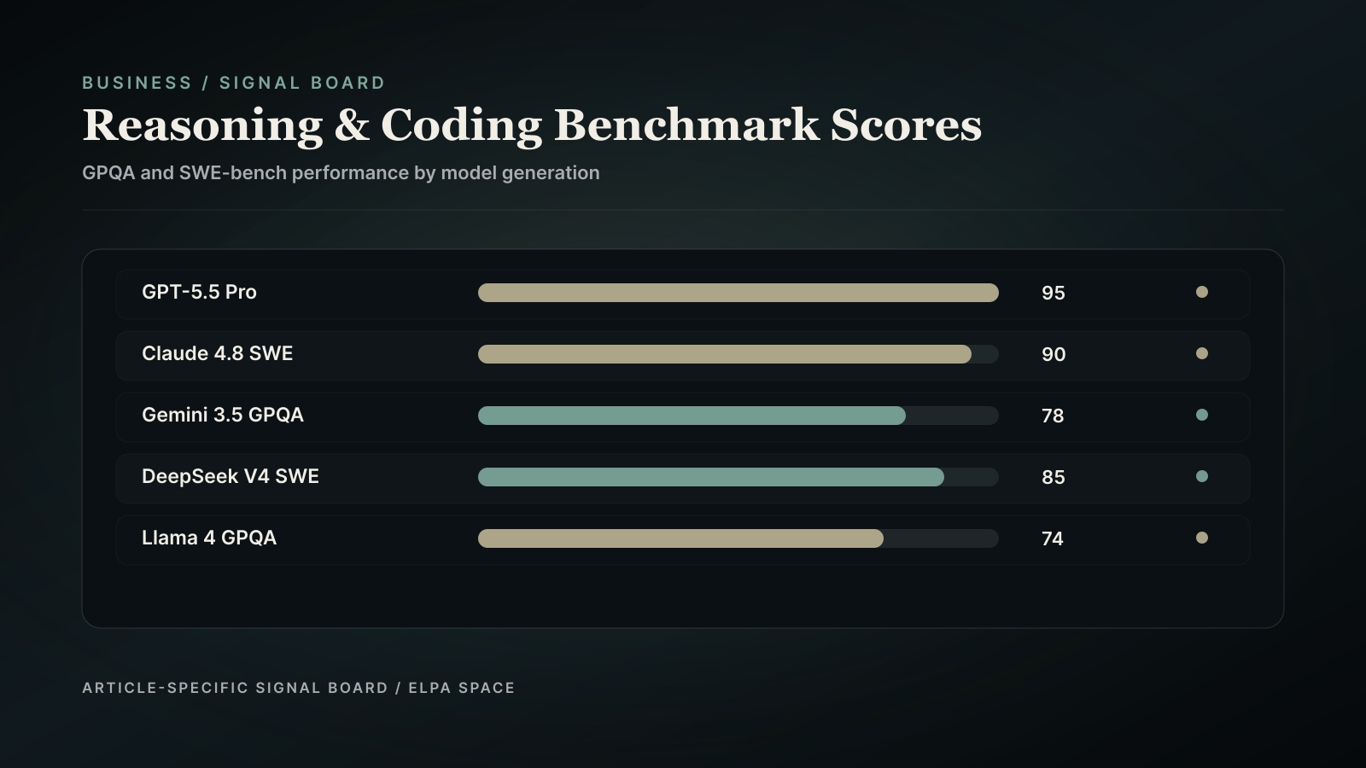
Benchmark results highlight Claude Opus 4.8 leading on SWE-bench code refactoring, while GPT-5.5 Pro leads on GPQA logic tasks.
## The Economics of Token Pricing
The token pricing models of leading AI providers vary significantly, with some models reaching record input costs of $30/M tokens and output costs of $180/M tokens. This has significant implications for project viability, as the cost of using high-end AI models can quickly add up.
Pay-per-token pricing models, such as those offered by DeepSeek and Llama, provide a cost-efficient alternative to subscription-based models. However, these models often come with limitations on input and output tokens.
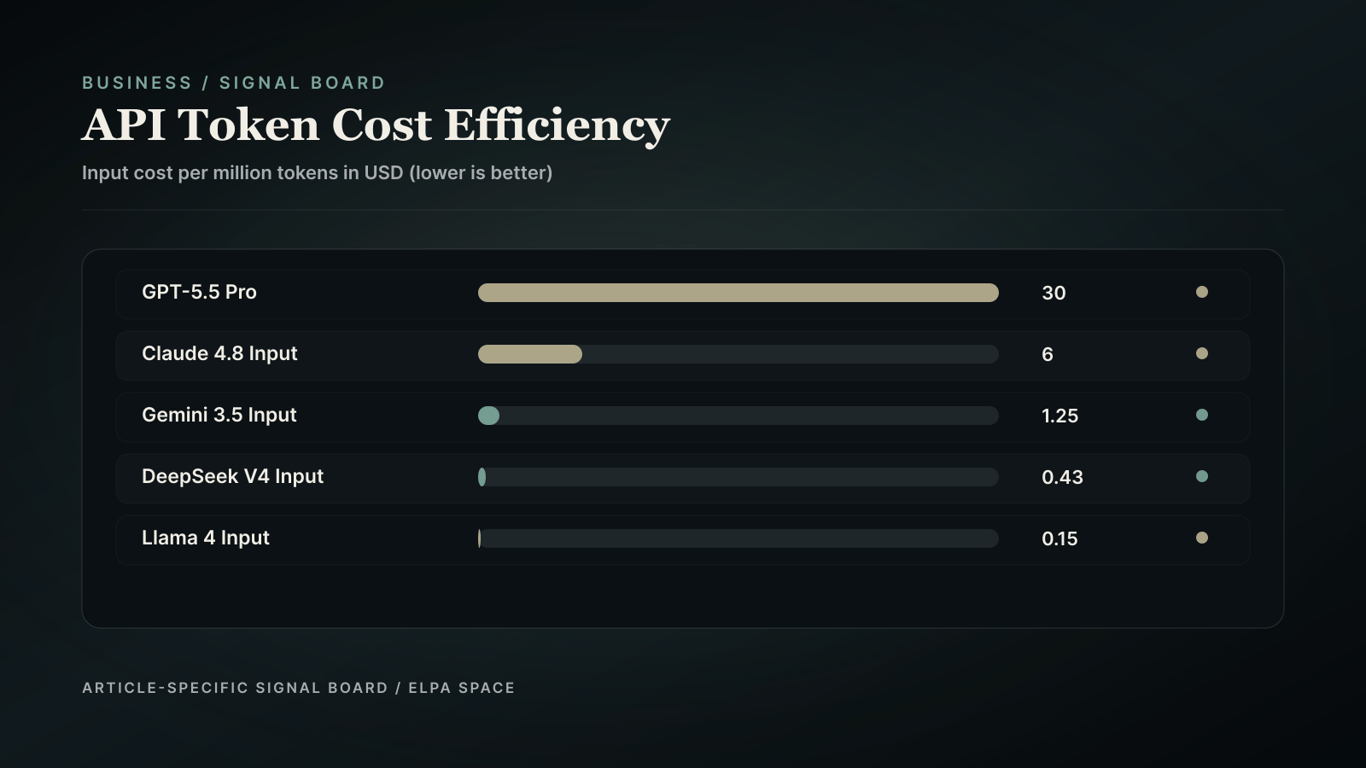
GPT-5.5 Pro at $30/M tokens represents a premium pricing tier, whereas DeepSeek V4 Pro and Llama 4 Maverick offer dramatic cost reductions.
## Balancing Logic and Latency
The trade-off between logic and latency is a critical consideration for AI projects. Models like GPT-5.5 Pro and Claude Opus 4.8 offer high-end reasoning capabilities but come with high latency costs. In contrast, models like Gemini 3.5 Flash prioritize low latency and real-time orchestration.
Google's Antigravity dynamic frontend rendering and agent tooling have enabled the development of real-time agentic loops, further blurring the lines between thinking and acting.
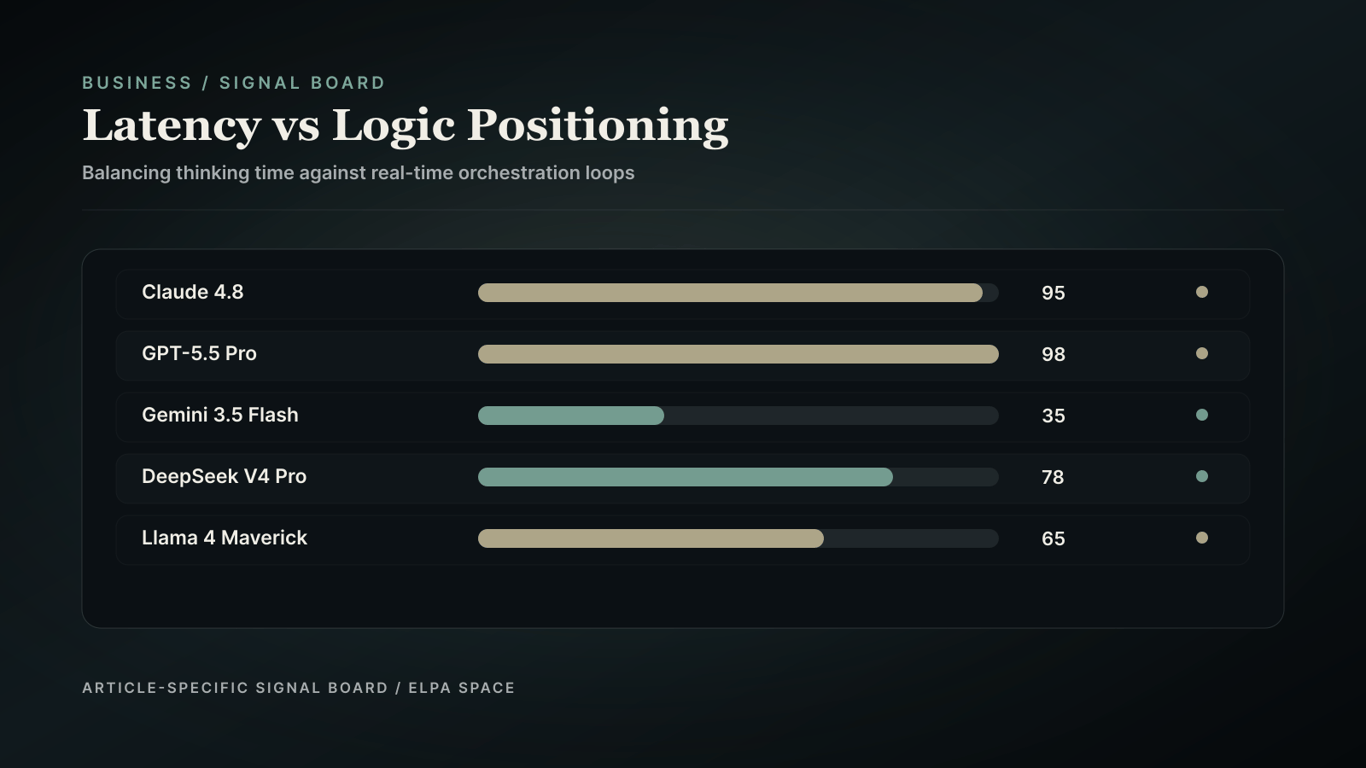
Gemini 3.5 Flash occupies the low-latency acting corner, whereas GPT-5.5 Pro and Claude 4.8 represent high-latency deep reasoning.
Factual Verdict
The strategic choice between high-end logic and cost-efficient routing depends on project requirements and budget constraints.